I’ve (well mostly Claude and Deepseek) shipped over 200-odd commits over the last seven weeks and most of the interesting work isn’t in the features themselves but in the discussions I had (with Claude), the assumptions that search benchmarks demolished, and the surprisingly deep rabbit hole that is getting an unsigned Mac app to actually launch. This is a writeup of the choices that mattered, why I made them and which ones I got wrong.
If you’re just interested in the final product: it’s a completely offline clipboard history manager for macOS, Windows and Linux with natural language semantic search that runs entirely on-device. No cloud, no account and no telemetry - https://tryyank.com.
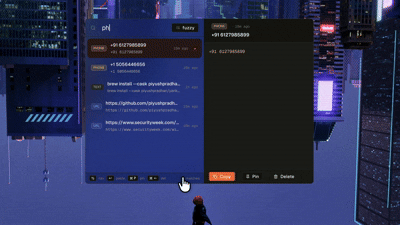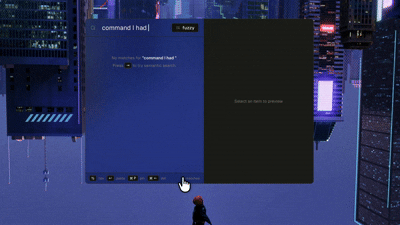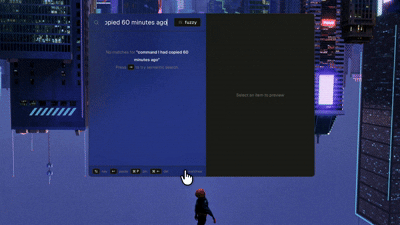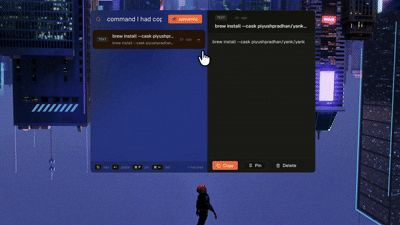
The shape of the thing
Yank is a Tauri app - Rust backend, React + TypeScript frontend with SQLite (using FTS5 and a vector column) as the single source of truth. The clipboard watcher polls the system clipboard at regular intervals and categorizes the contents into one of ten buckets - code, link, text, color, email, phone, path, address, number, image.
The most interesting feature, the semantic search, is powered by Reciprocal Rank Fusion (RRF) of BM25 keyword matching and cosine similarity over embeddings created by a local model that runs on-device by default. A lot of technical words I know, it took me a while to figure this out as well which is why I wanted to share it.
Phase 1: Shipping a very basic version of semantic search locally
This is what I had in mind as the star feature for this project, none of the clipboard history managers I had used had the feature where you can just say “the phone number I copied yesterday” and find that. The catch is that “AI search” usually means “give us an API key and send your clipboard data to a server” which I can understand would make a few people like me a bit skeptical.
So the semantic search in Yank is powered by a local embedding model that runs on your machine. This model is downloaded once (~130MB) from Hugging Face and after that the app is fully offline. OpenAI, Ollama and Anthropic are available as overrides if you want them but the default path needs no key, no network, no account.
The tradeoff is a chunky binary and one-time download. The payoff though, is that the headline feature works the instant you install and your clipboard is not shared with any third party.
How it all works
There are two modes for searching - fuzzy search and semantic search.
1. Fuzzy Search
This is pretty commonly used in a lot of applications, so this was pretty straightforward. Any time you know some part of what you’re looking for — a variable name, a URL, a word or phrase from the paragraph you copied — Yank uses fuzzy search powered by SQLite’s FTS5 extension.
2. Semantic Search
This is where the magic happens, a lot of the times you don’t remember the exact substring you want to search for but you remember what you were looking for so you just describe it briefly and Yank tries to figure out which of the copied items match the description the best.
Some cool things I learned along the way:
-
FTS5 creates a virtual table that indexes every word in your clipboard history. This allows for “keystroke-level fast” searching that doesn’t lag as your history grows.
-
It utilizes BM25 ranking algorithm which lets you adjust the parameters for “Term frequency & saturation” and “Document Normalization” to adjust how search results are ranked so I’ve been playing around with it to find out what gives the best results for my use case.
Phase 2: Improving the semantic search
Reciprocal rank fusion
Yank uses a technique called Reciprocal-Rank-Fusion (RRF) to merge the outputs of the BM25 fuzzy search and the semantic cosine similarity scores. RRF is a “remarkably robust” method that ranks clips based on their position in both search lists rather than their raw scores. The idea is that a clip relevant to both the literal keywords and the conceptual meaning should rise to the top — though, spoiler for Phase 3, “best of both worlds” turned out to be more of an aspiration than a guarantee.
Managing time properly
Embeddings are great at what and terrible at when. “4 days ago” and “last week” carry almost no semantic content worth embedding - but stuff them into the query vector and they will pollute the results, because “I copied” and “last week” are common phrases that drag the vector toward the noise instead of focusing on the actual content.
To make it look past the noise, Yank has an offline regex parser that strips temporal phrases before embedding and maps them to SQL created_at BETWEEN bounds. “5th January”, “yesterday”, “last week” now filter correctly without touching the vector at all. A pure time query like “stuff from yesterday” with no semantic residue skips embedding entirely and just returns the items created in the mentioned time range.
The pattern here is one that kept repeating: don’t ask one mechanism to do a job a cheaper, more precise mechanism does better. Embeddings are for meaning, regex for dates, BM25 for exact keyword matching, and RRF to mix them together.
Adding colors to my life
Colors were a fun feature to build. Yank categorizes copied items, so the moment you paste #4b0082 it lands in the color bucket. Searching for it later was the problem — the embedding model has no idea that #4b0082 is “indigo”, and BM25 just sees a six-character hash. Typing “indigo” found nothing.
The fix is two-sided.
At index time, when a clip is categorised as color, I parse the value to RGB and find the four closest CSS named colours by Euclidean distance, then staple them onto the document text before embedding. Now both BM25 and the vector path can find it by name without the embedder needing to learn any colour geometry.
At query time, a small detector runs before embedding to look for explicit colour intent — either a raw value (#4b0082, rgb(75, 0, 130), hsl(...)), a CSS named colour (indigo, dark blue), or a name paired with a colour marker word (orange hex code, red swatch, palette gold). If it fires, the query resolves to a concrete (r, g, b) target.
This is something super obvious I had somehow missed but Claude was clever enough to point it out. Single-token colour names turned out to be a landmine. “navy” the military branch, “orange” the fruit, “snow” the weather, “olive” the food, “rose” the flower — all are CSS colour names. The first version happily promoted a hex code for a query like “navy ship documentation”. So I split the names into two buckets: unambiguous ones (indigo, crimson, fuchsia, chartreuse, …) still fire on a bare match because nobody types “crimson” unless they mean the colour, while ambiguous ones only fire when there’s extra evidence — a marker word in the query, another colour name, or a query that’s just the colour word with nothing else around it (bare “navy” is still a colour request, because what else could it be?). Two-word CSS compounds (dark blue, hot pink, light coral) bypass the gate entirely since they’re not idiomatic English outside a colour context.
When the query does resolve to an RGB target, the search adds a small ranking boost to stored colour items based on their perceptual distance from the target. The boost is bounded, it clears the headroom an unrelated item could reach from BM25 plus vector combined for a near-exact match, and decays linearly to zero at a distance of 64 in RGB space, so only genuinely-close swatches get promoted. Crucially, the boost is scoped to items in the color category, so the worst it can do is reorder swatches it can never push a code block or paragraph above the colour you actually copied (I had to do this when I noticed there were code blocks or paragraphs that mentioned “color” in some way also came up in the results).
Same lesson as the time parser, really: a colour’s “meaning” is a 3D point in RGB space, and asking a 384-dim text embedder to learn that geometry is a bad job for it. A few lines of arithmetic on the actual values does it better.
Phase 3: Measuring if any of this actually works
Once everything was wired up - RRF, time parsing, the color name index, the category boost - I needed to know if any of it was actually doing what I hoped. So I built a retrieval-quality eval: 136 seeded clipboard items spanning ~2 years of synthetic history, 56 natural-language queries with hand-labeled ground truth, run through BM25-only, Vector-only, and the two Hybrid generations - measuring P@1, P@5, P@10 and MRR for each.
The first version of this eval told me what I wanted to hear. BM25-only at P@1 = 0.80, Hybrid at 0.90, big satisfying chart. Except the queries were things like “biryani recipe” pointing at the item “Recipe: biryani, 250g of Chicken, 4 onions…”. The query literally contained the answer word. BM25 was acing the test because the test was a keyword test in disguise.
So I asked Claude to rewrite the query set with a 20/80 split. About a fifth of the queries keep deliberate keyword overlap - the cases where users actually do type the exact brand or term (“biryani recipe”, “salesforce account id”, “useEffect cleanup”). The other 80% are paraphrases that share no word stems with the relevant item: “how nana makes those crunchy cocoa treats” pointing at “Grandma’s chocolate chip cookies”, “the secret string for connecting to the internet” pointing at “House WiFi password”, “swap american money for european money” pointing at the USD/EUR currency note. To keep myself honest, I added an auto-classifier to the eval that walks the FTS-indexed fields of every relevant item and flags any 4-char stem overlap - so the lex/sem split is computed from the data, not from my labels.
The numbers got a lot more honest:
Lexical-overlap subset (the 20% where the query reuses an item word):
| strategy | P@1 | P@5 | MRR |
|---|---|---|---|
| BM25-only | 1.000 | 0.595 | 1.000 |
| Vector-only | 0.818 | 0.273 | 0.909 |
| Hybrid v3 | 0.818 | 0.327 | 0.909 |
| Hybrid v4 | 0.909 | 0.436 | 0.955 |
Semantic-only subset (the 80% where the user paraphrases):
| strategy | P@1 | P@5 | MRR |
|---|---|---|---|
| BM25-only | 0.022 | 0.004 | 0.027 |
| Vector-only | 0.511 | 0.156 | 0.612 |
| Hybrid v3 | 0.111 | 0.104 | 0.232 |
| Hybrid v4 | 0.133 | 0.104 | 0.244 |
The lex subset is the boring case - BM25 is perfect because the query literally contains the answer. The semantic subset is what I actually care about, and it broke two of my priors.
BM25 totally collapses on paraphrase. A P@1 of 0.022 means it returns the right answer roughly 1 in 50 times when the user doesn’t reuse the item’s vocabulary. The moment somebody types “swap american money for european money” instead of “USD to EUR”, you lose. “Just use FTS5” is fine if your users phrase their searches the way they originally phrased their clipboard contents - which, in practice, they don’t.
Vector-only beats Hybrid on the semantic subset. This one I didn’t expect. The whole point of RRF was supposed to be that you got the best of both - but on paraphrase queries Vector-only is ~4× ahead of both Hybrid generations on P@1.
The culprit, after some digging, is a 0.15 cosine-similarity threshold I have on the vector pool inside the hybrid path. The reasoning was defensible: drop “obviously orthogonal” vectors so a stale recency boost couldn’t push them above genuinely-relevant matches. But on paraphrase queries the right item often sits just below 0.15 similarity - close enough that pure vector ranking still finds it at rank 1, but too low to survive the hybrid threshold. And because BM25 contributes essentially nothing for those queries (the FTS pool is empty too), there’s nothing for RRF to fuse - the answer drops out of the pool entirely and you get a miss.
The biased eval hid this completely. Because the old queries shared words with the items, the BM25 pool was always populated and the vector pool always cleared the threshold - everything looked great in aggregate. The unbiased eval surfaces it in a single number. Lowering the threshold (or dropping it entirely when the BM25 pool comes back empty) is the obvious next fix.
The lesson - the one I gestured at in the intro about assumptions search benchmarks demolished - is that when your benchmark agrees too easily with what you wanted to be true, that’s the time to be most skeptical of it. A benchmark that only tells you you’re right is doing the easy job. A benchmark that splits its results by whether the question was an easy one is doing the useful job.
Phase 4: Stress testing the search at scale
Once the time parsing, RRF and the category boost were all working, I had a different worry. Yank’s database grows forever - no rotation, no archive tier, no “old clips fall off.” If I copy 50 things a day, I’ll cross 100k items by year five. Will the search still feel instant by then?
The vector path was the one I was nervous about. Yank stores embeddings as a BLOB column on every row and does a brute-force cosine scan over the whole table - no ANN index, no IVF clusters, nothing fancy. Brute force is great until it isn’t.
So I wrote a load test harness, a small example binary that:
- Embeds 20 content templates and 15 queries once using the real BGE-small ONNX model.
- For each N in {1k, 10k, 50k, 100k}, seeds a fresh SQLite DB by cloning template embeddings across N synthetic items. Actually embedding all 100k items at real CPU speed would take ~80 minutes; cloning takes 1.7 seconds.
- Warms the SQLite page cache, then runs 20 iterations × 15 queries × 3 strategies and records p50, p95, and max.
The trick with cloning is that vector search latency only depends on N and the embedding dimension, not on the actual vector values. So the timings are honest even though the ranking is meaningless for this particular test.
Here’s what came out on my M-series laptop with NVMe storage:
| N | BM25 p50 | Vector p50 | Hybrid p50 |
|---|---|---|---|
| 1,000 | 0.07 ms | 0.68 ms | 0.79 ms |
| 10,000 | 0.48 ms | 7.72 ms | 8.25 ms |
| 50,000 | 2.56 ms | 43.08 ms | 45.88 ms |
| 100,000 | 5.54 ms | 91.01 ms | 98.15 ms |
Three things jumped out:
BM25 is essentially free. Going from 1k to 100k items, a 100× increase, moves p50 from 0.07 ms to 5.54 ms - that’s only about 80×. The FTS5 index is doing its job: the cost scales with the number of matching rows, not the total row count. The tail latency (p95 of 27 ms at 100k) is driven by queries that match a lot of candidate rows and actually have to sort them, but none of it is anywhere near user-visible.
Vector search is metronomically linear. It goes from 0.68 ms to 91 ms across the same growth - almost exactly linear, slope of ~0.91 ms per 1,000 items. The variance is striking too. p95 is barely above p50 at every N, because the algorithm doesn’t care what you query - it reads every row, computes a 384-dim dot product, partial-sorts the top 50. No early termination, no shortcut. That’s both a curse (the cliff is coming) and a blessing (no pathological queries, you can predict p99 from N alone).
Hybrid pays a small flat premium over vector. About 5-10 ms extra, which is exactly the cost of the second BM25 pass plus the RRF fusion - both O(pool size), capped at 50. The fusion doesn’t grow with N, so the hybrid curve stays parallel to vector. Which means semantic mode in production has no extra scaling risk vs. raw vector, which is what I was hoping.
If I extrapolate the line: at 250k items hybrid p50 lands around 245 ms, which is where the keystroke-to-result loop starts to feel laggy. At 500k it’s around 490 ms - the palette feels broken. So I have headroom until somewhere between 150k and 250k items, roughly 3-5 years of heavy use, before I need an actual ANN index (probably sqlite-vec since it slots into the same SQL shape I already use).
For now though, the right call is to not optimize. Premature ANN indexing would add complexity and rebuild cost on every embedder swap for zero current win. The plan is to add a soft tripwire at 150k items that suggests enabling an experimental flag once we ship one, and re-run this bench every time the embedder changes - a future BGE-base would push the per-row dot product to 768 dims, a 2× hit on every cell of that table.
The other lesson, less load-test-y: this whole experiment took an evening. If you’re shipping a desktop app with a vector column and no ANN index, you should know exactly where your latency cliff is. It’s surprisingly cheap to find out.
Where it stands
Seven weeks and a little over 200 commits later, the thing I actually wanted exists: a clipboard manager you can talk to in plain English that never once phones home. The semantic search works the moment you install it, it holds up to roughly five years of my copying habits, and I know the exact point where it’ll start feeling slow long before I have to do anything about it.
It’s not finished though. The eval caught me shipping a hybrid mode that loses to plain vector search on the precise queries I built the feature for, and the fix — dropping that 0.15 threshold when the keyword pool comes back empty — is still sitting in a branch instead of a release. That’s the honest status. The benchmark did its job. Now I have to do mine.
If there’s one thing this project kept teaching me, it’s almost embarrassingly simple: stop making one tool do a job a dumber, cheaper tool does better. Dates went to regex, colours to plain arithmetic, exact words to BM25, and the embedder only ever had to carry actual meaning. Nearly every bug I hit was me forgetting that and asking a 384-dimension text model to be clever about something it has no business being clever about.
Next up is killing that threshold bug, then a soft tripwire at 150k items so future-me gets a nudge before the latency cliff instead of a faceful of it. After that, probably sqlite-vec — but not a second before I actually need it.
Yank is free and fully offline at tryyank.com. Go copy something weird and see if you can find it again next week.